
IT STUDY LOG
Sprint - Auto Scaling + CloudWatch를 이용한 알림 본문
Sprint - Auto Scaling + CloudWatch를 이용한 알림
roheerumi 2023. 6. 2. 13:24# 학습 목표
- 갑작스러운 트래픽 증가에 대응하기 위해서는, 서버의 주요 메트릭을 모니터링하고, 특정 메트릭이 임계치를 넘을 때, 수평 확장이 자동으로 진행되게 하는 것이 바람직
- 스프린트를 통해 ASG의 원리를 익히고, 메트릭에 따른 스케일링 정책을 세우고 모니터링을 통해 정책이 적용되는지 확인
- 추가적으로 모니터링을 통해 모든 지표를 항상 관찰할 수 없으므로, 주요 메트릭의 임계치, 또는 장애 발생 예상 시점(예를 들어, CPU 사용량이 80%에 도달할 경우)을 경보의 형태로 제공해야 하는데 이를 기존에 익혔던 SNS 및 람다를 통해 구현
- CloudWatch를 통해 로그 및 그래프를 볼 수 있음
- CloudWatch를 통해 경보를 설정할 수 있음
- 오토 스케일링 원리를 복습하고, CloudWatch 및 SNS, Lambda를 통해 경보가 전달되는 메커니즘을 이해하고 구현 가능
# 해결 과제
💡 EC2 서버를 ASG를 통해 구성
💡 CloudWatch 알람을 통해 ASG의 스케일 인/아웃을 진행
💡 스케일 인/아웃이 진행될 때 디스코드에 알림
💡 메트릭을 바탕으로 장애 발생 예상 시점에 디스코드에 알림 - CPU 사용률(CPUUtilization) 값이 특정 값 이상일 때 경보가 발생
# 실습 자료 및 참고 사항
과금 관련 내용
- ASG
- ASG 그 자체는 과금되지 않으나, CloudWatch 사용 및 EC2 리소스 사용에 따른 과금이 발생
- CloudWatch
- 경보 지표당 월 $0.10
- [세부 CloudWatch 모니터링]을 사용하면, 1분마다 지표를 업데이트 (지표 확인에 매번 5분을 기다리기 힘들다면 사용)
- 세부 모니터링을 사용하지 않으면 지표 업데이트 주기는 5분이며, 이 경우 요금은 무료
- 세부 CloudWatch 모니터링 요금 정책 확인
- 월별로 인스턴스당 $2.10의 요금(인스턴스당 7개 지표 가정)
제출 관련 내용
- Discord 웹훅이 실제로 전송되면 제출로 간주하므로 본인 이름을 username에 적어내기
# 과제 항목별 진행 상황
✏️ 사전 작업
- 로드밸런서 설정은 하지 않아도 됨
Step 1 : 시작 템플릿 구성
1) 시작 템플릿 구성 정보
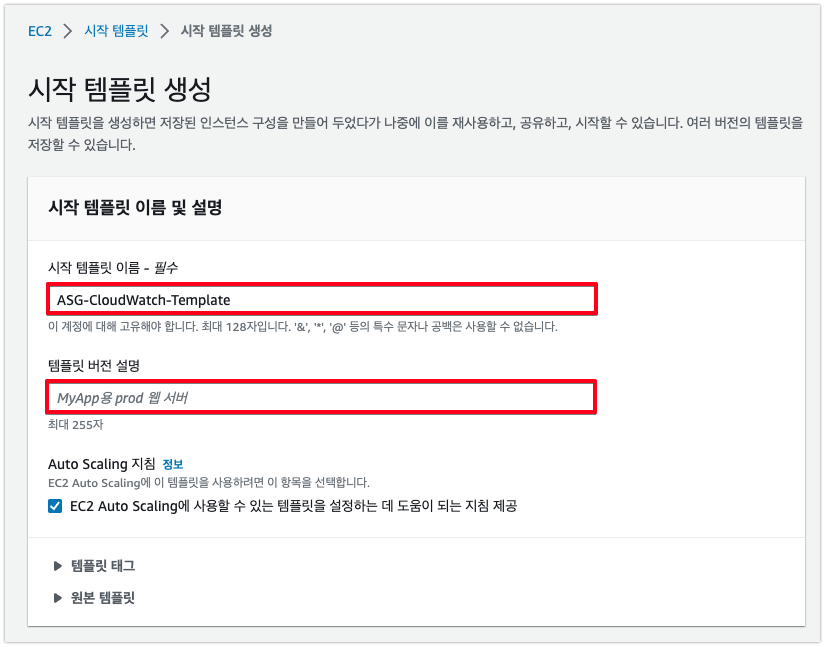


- Ubuntu Server (LTS)
- t2.nano
- 기존 혹은 신규 키 페어를 사용
- 보안 그룹: 인바운드 HTTP 및 SSH 허용
- 사용자 데이터
#!/bin/bash
echo "Hello, World" > index.html
sudo apt update
sudo apt install stress
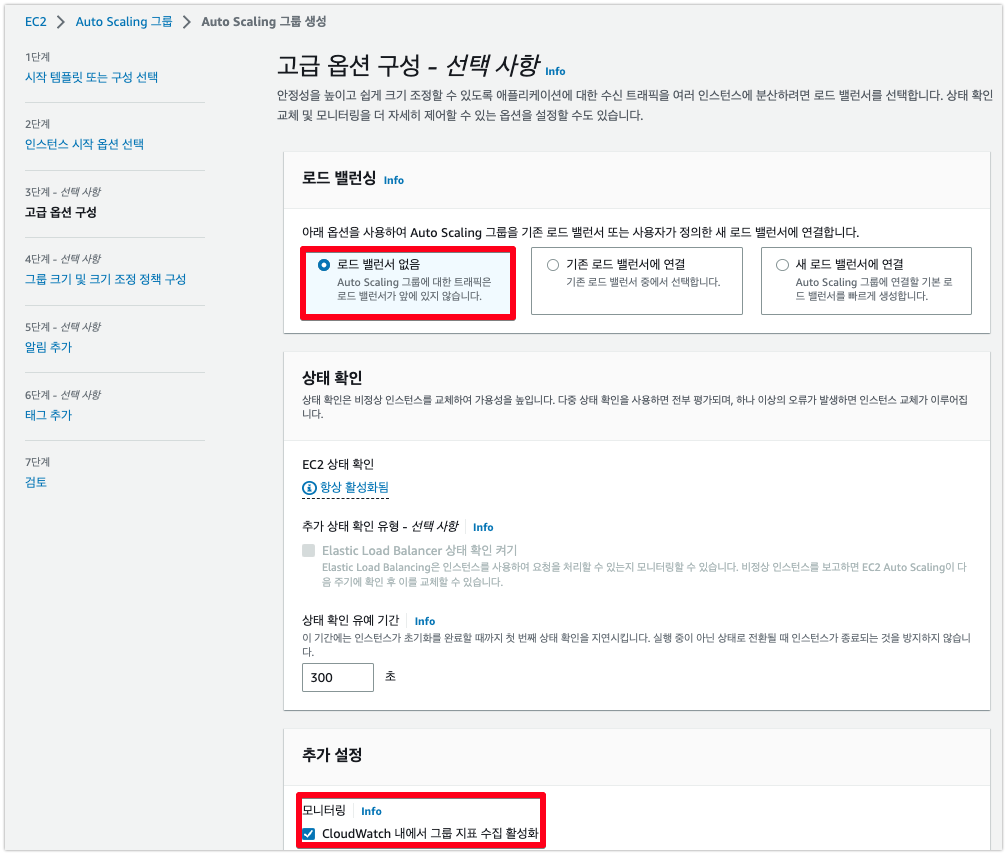
nohup busybox httpd -f -p 80 &2) Auto Scaling group 구성
- 원하는 용량: 1
- 최소 용량: 1
- 최대 용량: 3




Step 2 : CloudWatch와 조정 정책
1) 지표 상한 및 하한 임계값에 대한CloudWatch 경보 생성
❶ 상한값에 대한 경보 생성
1. https://console.aws.amazon.com/cloudwatch/에서 콘솔 선택 후 필요한 경우 리전을 변경. 이후 탐색 모음에서 Auto Scaling 그룹이 상주하는 리전을 선택하고, 탐색 창에서 경보(Alarms), 모든 경보(All alarms)를 선택한 다음 경보 생성(Create alarm)을 선택
2. 지표 선택(Select metric)을 선택
- 모든 지표(All metrics) 탭에서 EC2, Auto Scaling 그룹 기준(By Auto Scaling Group)을 선택하고 검색 필드에 Auto Scaling 그룹 이름을 입력 그런 다음 CPUUtilization을 선택하고 지표 선택(Select metric)을 선택


3. 지표에 대한 그래프와 기타 정보가 표시된 지표 및 조건 지정(Specify metric and conditions) 페이지가 나타남


- 기간(Period)에 예를 들어 1분과 같은 경보에 대한 평가 기간을 선택. 경보를 평가할 때 각 기간이 하나의 데이터 포인트로 집계 (참고 : 기간이 짧을수록 경보가 더 민감해짐)
- 조건(Conditions)에서 다음을 수행
- 임계값 유형(Threshold type)에서 정적(Static)을 선택
- CPUUtilization가 다음과 같은 경우 항상에서 지표 값이 임계값보다 클 때, 크거나 같을 때, 작을 때, 작거나 같을 때 중 경보를 트리거할 조건을 지정 그런 다음 기준(than)에 경보를 위반하려는 임계값을 입력
- [중요] 스케일 아웃 정책(지표 상한)과 함께 사용할 경보의 경우 임계값보다 작은 항목이나 작거나 같은 항목을 선택하지 않았는지 확인 스케일 인 정책(지표 하한)과 함께 사용할 경보의 경우 임계값보다 큰 항목이나 크거나 같은 항목을 선택하지 않았는지 확인
- 추가 구성(Additional configuration)에서 다음을 수행
- 경보에 대한 데이터 포인트(Datapoints to alarm)에서 지표 값이 경보에 대한 임계값 조건을 충족해야 하는 데이터 포인트(평가 기간)를 입력 (예를 들어 5분의 시간이 두 차례 연속되면 경보 상태를 호출하기까지 10분이 걸림)
- 누락 데이터 처리(Missing data treatment)에서 누락 데이터를 불량으로 처리(임계값 위반)(Treat missing data as bad (breaching threshold))를 선택 (자세한 정보는 AmazonCloudWatch 사용 설명서 의 CloudWatch경보가 누락된 데이터를 처리하는 방법 구성을 참조)
4. 작업 구성 페이지가 표시되면 알림(Notification)에서 경보가 ALARM 상태, OK 상태 또는 INSUFFICIENT_DATA 상태일 때 알릴 Amazon SNS 주제를 선택경보에서 알림을 보내지 않게 하려면 제거(Remove)를 선택
- 경보가 동일한 경보 상태 또는 다른 경보 상태에 대해 여러 개의 알림을 보내도록 설정하려면 알림 추가(Add notification)를 선택

- 작업 구성(Configure actions) 페이지의 다른 섹션은 비워둘 수 있으며 다른 섹션을 비워 두면 조정 정책에 연결하지 않고도 경보가 생성되므로 그런 다음 Amazon EC2 Auto Scaling 콘솔에서 경보를 조정 정책에 연결 가능
5. 경보의 이름(예: Step-Scaling-AlarmHigh-AddCapacity)과 설명(선택 사항)을 입력하고 다음(Next)을 선택 후 경보 생성(Create alarm)을 선택
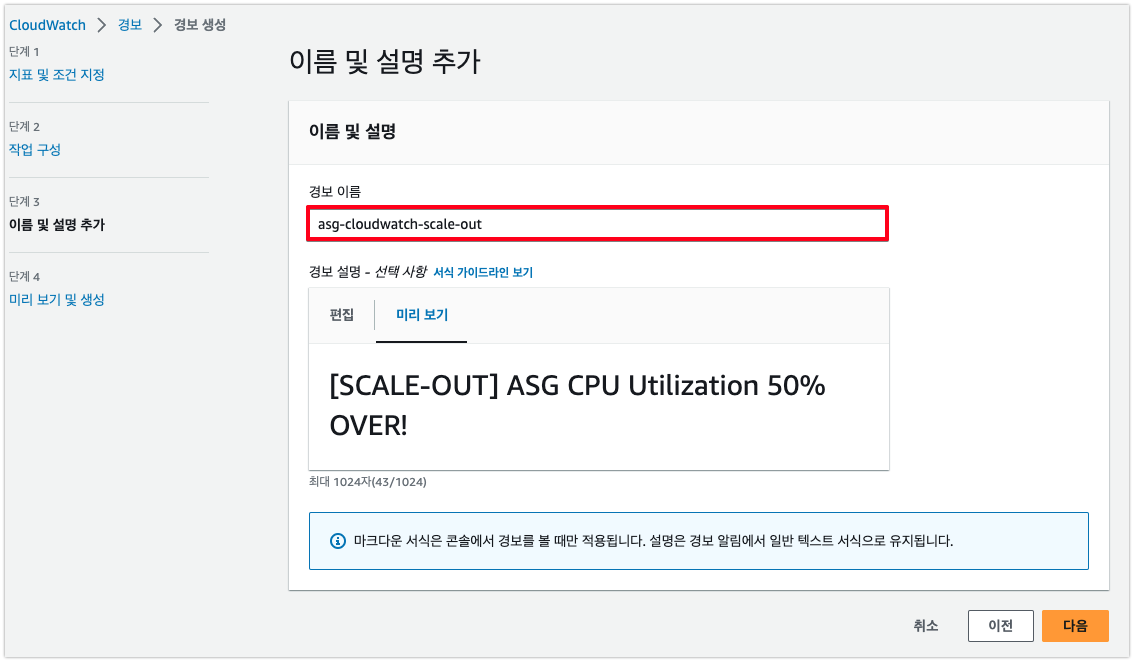
❷ 하한값에 대한 경보 생성 - 동일한 과정에서 조건, 이름만 변경



❸ CloudWatch에서 정상적으로 경보 생성되었음 확인

2) 조건 CPU 50% 이상의 Scale-out 조정 정책 생성
❶ https://console.aws.amazon.com/ec2/에서 Amazon EC2 콘솔을 열고 탐색 창에서 Auto Scaling Groups(Auto Scaling 그룹)를 선택 후 Auto Scaling 그룹 옆의 확인란을 선택 > Auto Scaling 그룹 페이지 하단에 분할 창 확인
- 최소 및 최대 크기 제한이 적절하게 설정되어 있는지 확인
(ex) 예를 들어 그룹이 이미 최대 크기인 경우 확장하려면 새로운 최댓값을 지정해야 함.
- Amazon EC2 Auto Scaling에서는 최소 용량 미만이거나 최대 용량을 초과하는 그룹은 조정하지 않으므로 그룹을 업데이트하려면 세부 정보(Details) 탭에서 최소 및 최대 용량에 대한 현재 설정을 변경
❷ 자동 크기 조정(Automatic scaling) 탭의 동적 크기 조정 정책(Dynamic scaling policies)에서 동적 크기 조정 정책 생성(Create dynamic scaling policy)을 선택
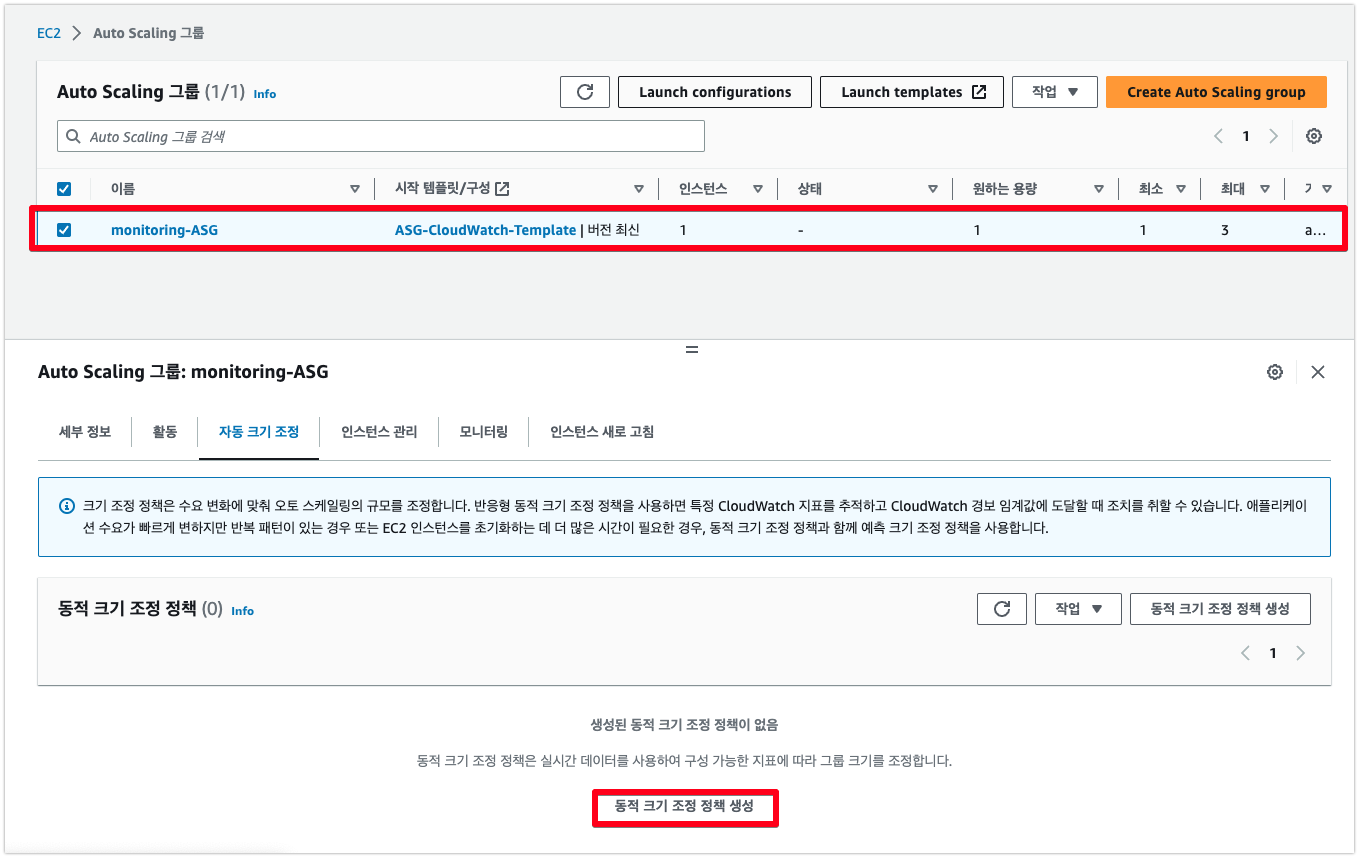
❸ 확장(용량 증가)을 위한 정책을 정의하기 위해 다음을 수행
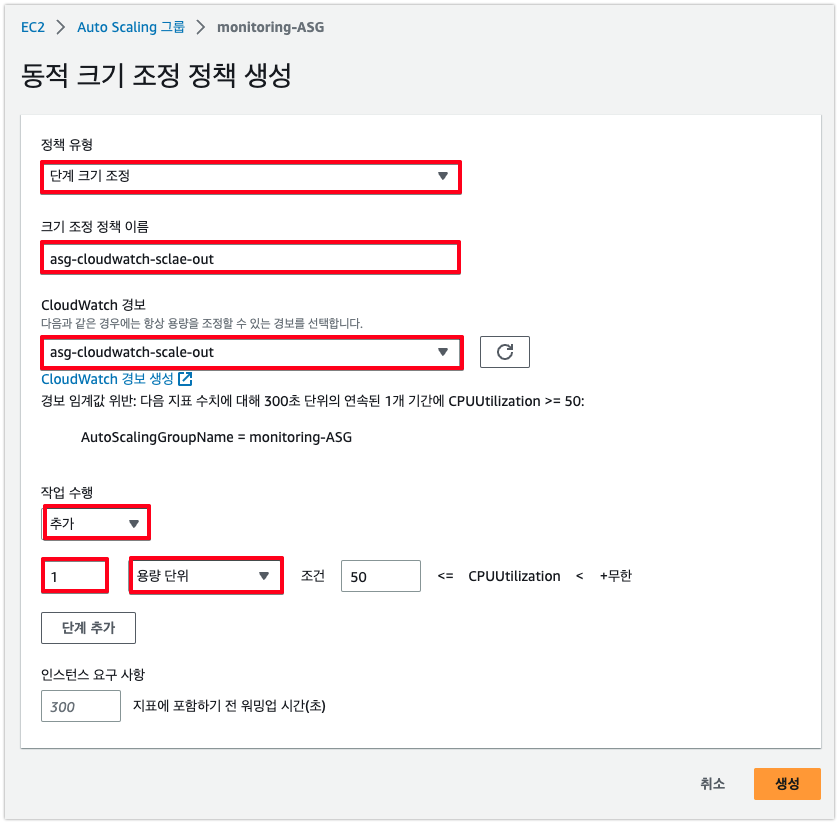
- 정책 유형(Policy type)에서 단계 조정(Step scaling)을 선택
- 정책의 이름을 지정
- CloudWatch알람의 경우 알람을 선택 (아직 경보를 생성하지 않은 경우 경보 생성을 선택하고 4단계부터 지표 상한 및 하한 임계값에 대한CloudWatch 경보 생성 (콘솔) 14단계까지 완료하여 CPU 사용률을 모니터링하는 경보를 생성할 것)
- 다음 작업을 수행(Take the action)을 사용하여 이 정책을 실행할 때 적용할 현재 그룹 크기 변경을 지정 특정 인스턴스 개수 또는 기존 그룹 크기의 백분율을 추가하거나 그룹을 정확한 크기로 설정 가능
- 추가, 제거 등의 작업이 존재하며 그룹 백분률, 용량 단위(인스턴스의 개수) 등 지정 가능
- 다른 단계를 추가하려면 단계 추가(Add step)를 선택한 다음 조정할 양과 경보 임계값에 상대적인 단계 하한 및 상한을 정의
- 조정할 최소 인스턴스 수를 설정하려면 최소 1 단위 용량의 증분으로 용량 단위 추가(Add capacity units in increments of at least 1 capacity units)의 숫자 필드를 업데이트
- (선택 사항) 인스턴스 필요(Instances need)에서 필요에 따라 인스턴스 워밍업 값을 업데이트
- 생성 선택
2) 조건 CPU 40% 이하의 Scale-in 조정 정책 생성

- 정책 유형(Policy type)에서 단계 조정(Step scaling)을 선택
- 정책의 이름을 지정
- CloudWatch알람의 경우 알람을 선택 (아직 경보를 생성하지 않은 경우 경보 생성을 선택하고 4단계부터지표 상한 및 하한 임계값에 대한CloudWatch 경보 생성 (콘솔) 14단계까지 완료하여 CPU 사용률을 모니터링하는 경보를 생성)
- 다음 작업을 수행(Take the action)을 사용하여 이 정책을 실행할 때 적용할 현재 그룹 크기 변경을 지정
- 특정 인스턴스 개수 또는 기존 그룹 크기의 백분율을 제거하거나 그룹을 정확한 크기로 설정 가능.
- 예를 들어 Remove를 선택하고 다음 필드에 2을 입력한 다음 capacity units을 선택. 기본적으로 이 단계 조정의 상한값은 경보 임계값이고 하한값은 음(-)의 무한대
- 다른 단계를 추가하려면 단계 추가(Add step)를 선택한 다음 조정할 양과 경보 임계값에 상대적인 단계 하한 및 상한을 정의
- 생성(Create)을 선택
✏️ 지표 수집 과정
- EC2 수집 주기의 기본값은 5분이며 ASG의 경우 [지표 수집 활성화]를 통해 지표를 CloudWatch에 기록하므로 기록을 이용해 시간에 따른 메트릭 추이를 확인 가능
- 경보를 통해 임계치에 따른 메시지가 SNS로 전달되며 ASG에서 발생하는 스케일링 이벤트를 트리거하기 위해 경보 두 개(스케일 인/아웃)를 자동으로 생성
❖ 참고로, CloudWatch의 메트릭 보존 기간은 수집 주기에 따라 다르며 세부 모니터링 옵션을 활성화하여 수집 주기를 조절 가능함(자세한 내용은 CloudWatch FAQ를 통해 확인)
Step 1 : 알림 및 경보 아키텍처

- 레퍼런스를 참고하여 CPU 사용률(CPUUtilization) 값이 특정 값 이상일 때 경보가 발생하게 메트릭 값에 따른 경보 생성
Step 2 : Lambda 코드
1) discord에 메시지를 보내는 lambda 함수 생성

import boto3
import json
import logging
import os
from base64 import b64decode
from urllib.request import Request, urlopen
from urllib.error import URLError, HTTPError
HOOK_URL = os.environ['HOOK_URL']
logger = logging.getLogger()
logger.setLevel(logging.INFO)
def lambda_handler(event, context):
logger.info("Event: " + str(event))
message = json.loads(event['Records'][0]['Sns']['Message'])
logger.info("Message: " + str(message))
discord_message = {
'username': 'CloudWatch Monitor',
'avatar_url': 'https://i.imgur.com/4M34hi2.png',
'content': 'Test'
}
if 'AlarmName' in message:
discord_message = {
'username': 'CloudWatch Monitor',
'avatar_url': 'https://i.imgur.com/4M34hi2.png',
'content': "AlarmName: %s \n OldStateValue: %s \n NewStateValue: %s " % (message['AlarmName'], message['OldStateValue'], message['NewStateValue'])
}
if 'Origin' in message:
discord_message = {
'username': 'CloudWatch Monitor',
'avatar_url': 'https://i.imgur.com/4M34hi2.png',
'content': "Origin: %s \n Cause: %s \n Event: %s " % (message['Origin'], message['Cause'], message['Event'])
}
payload = json.dumps(discord_message).encode('utf-8')
headers = {
'Content-Type': 'application/json; charset=utf-8',
'Content-Length': len(payload),
'Host': 'discord.com',
'user-agent': 'Mozilla/5.0'
}
req = Request(HOOK_URL, payload, headers)
try:
response = urlopen(req)
response.read()
logger.info("Message posted to discord")
except HTTPError as e:
logger.error("Request failed: %d %s", e.code, e.reason)
logger.error(e.read())
except URLError as e:
logger.error("Server connection failed: %s", e.reason)2) lambda 환경변수 설정

3) lambda 트리거에 경보를 생성한 SNS 추가

- SNS에 정상적으로 구독되었는지 확인

✏️ 부하 테스트
STEP 1 : 생성된 ASG 인스턴스 하나에 접속해 부하테스트 수행
# CPU 사용률을 100%로 만드는 명령어
$ stress -c 1
stress: info: [1958] dispatching hogs: 1 cpu, 0 io, 0 vm, 0 hdd

STEP 2 : 생성된 ASG 인스턴스 두 개에 접속해 부하테스트 수행


STEP 3 : 정상적으로 Scale-out 되고 디스코드로 메시지가 전송되었는지 확인


STEP 4 : 부하테스트 종료 후 정상적으로 Scale-in 되었는지 확인

#References
https://docs.aws.amazon.com/ko_kr/autoscaling/ec2/userguide/ec2-auto-scaling-sns-notifications.html
Auto Scaling 그룹 조정 시 Amazon SNS 알림 수신 - Amazon EC2 Auto Scaling
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사 실망시켜 드려 죄송 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/monitoring/US_AlarmAtThresholdEC2.html
CPU 사용량 경보 생성 - 아마존 CloudWatch
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사 실망시켜 드려 죄송 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
AWS CloudWatch지표를 게시하는 서비스 - 아마존 CloudWatch
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사 실망시켜 드려 죄송 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
https://docs.aws.amazon.com/ko_kr/AWSEC2/latest/UserGuide/viewing_metrics_with_cloudwatch.html
인스턴스에 사용 가능한 CloudWatch 지표 나열 - Amazon Elastic Compute Cloud
인스턴스에 사용 가능한 CloudWatch 지표 나열 Amazon EC2는 측정치를 Amazon CloudWatch로 전송 AWS Management Console, AWS CLI 또는 API를 사용하여 Amazon EC2가 CloudWatch로 전송하는 지표를 나열할 수 있습니
docs.aws.amazon.com
Amazon EC2 Auto Scaling의 단계 조정 및 단순 조정 정책 - Amazon EC2 Auto Scaling
PercentChangeInCapacity - 그룹의 현재 용량을 지정된 퍼센트만큼 늘리거나 줄입니다. 양의 값은 용량을 늘리고, 음의 값은 용량을 줄입니다. 예제: 현재 용량이 10개이고 조절이 10%인 경우 이 정책이
docs.aws.amazon.com
https://docs.aws.amazon.com/ko_kr/AmazonCloudWatch/latest/monitoring/US_AlarmAtThresholdEC2.html
CPU 사용량 경보 생성 - 아마존 CloudWatch
이 페이지에 작업이 필요하다는 점을 알려 주셔서 감사 실망시켜 드려 죄송 잠깐 시간을 내어 설명서를 향상시킬 수 있는 방법에 대해 말씀해 주십시오.
docs.aws.amazon.com
'devops bootcamp 4 > pair/team log' 카테고리의 다른 글
| Sprint - aws EC2와 K6를 이용한 성능테스트 (0) | 2023.06.07 |
|---|---|
| Sprint - 모니터링 시스템 구축 (0) | 2023.06.05 |
| Sprint - 새 버전이 망가졌어요 (0) | 2023.05.19 |
| Sprint - Terraform x AWS (0) | 2023.05.17 |
| Sprint - 서버리스 애플리케이션 (0) | 2023.05.11 |



